New Insights

Statu Quo
Components in traditional OS kernels can interfere with each other in arbitrary way.
- A single kernel bug can wreck the entire system's integrity and protection.
- Poor support for recovery and security.
- Very difficult to design and maintain.
Clean-State Kernel
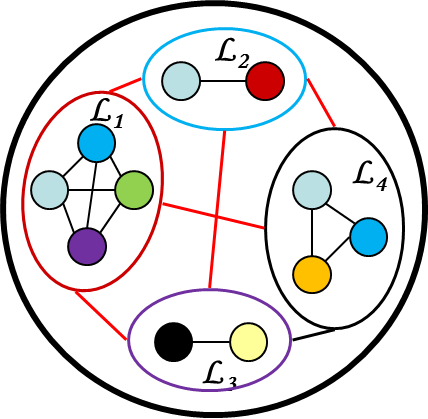
Only limited features at certain abstraction layer are used in specific kernel modules.
- Structure the kernel using certified abstraction layers.
- Minimize unwanted interferences and maximize modularity and extensibility.
- Each component could be certified separately and linked by the layer framework.
Our Approach

Design of Clean-State Kernel
The entire kernel is composed of modular, replaceable, and individually certifiable plug-ins.
- Different plug-in classes implement different kernel functions.
- Embody different safety and correctness models.
- Each kernel extension is not just "safe" but also "semantically correctly".
- Protected executors replace the traditional "red line".
A Layer Based Framework
A layered based framework to certify low-level system.
- A new layer calculus showing how to formally specify, program, verify, and compose certified abstraction layers.
- Supporting layered programming at both C level (ClightX) and assembly level (LAsm).
- Extend CompCert to build a new verified compiler, CompCertX, that can compile ClightX abstraction layers into LAsm layers.

Formal Techniques
Deep Specification
The deep specification captures all the observable behavior of the implementation.
- Deep specification is a relative concept regarding the observable behavior.
- Any two implementations of the same deep spec are contextually equivalent.
- All the property about the implementation can be proved using deep specification alone.
Deep Specification is an abstract concept.
- It still abstracts away the concrete data representation, implementation algorithm, and strategies.
- It can still be nondeterministic by having external nondeterminism (e.g. I/O or scheduler events) modeled as a set of deterministic traces relate to external events as well as internal nondeterminism (e.g. sqrt, rand, resource-limit).
- It adds new logical info to make it easier to reason about auxiliary abstract states to define the full functionality and invariants, and accurate precondition under which each primitive is valid.

Certified Abstraction Layer
Contextual Refinement between Sequential Layers

Certified abstraction layer is a deep specification of the implementation.
- An abstraction layer is a triple (L1, M, L2).
- The module M implements the overlay interface L2 on top of underlay L1.
- After abstracting away the memory operation in underlay (L1) as the operation over abstract state in overlay (L2), layers over the overlay (L2) do not need to look up the memory region already excluded in L1.
- The relationship between two layers are based on a simulation proof, which implies that when L2 takes one step from s1 to s1', and s1 and s2 is on a relationship R, there exists a state s2' that satisfies the relationship on R with s1' and is a result of more than one step evaluations from s2 by L1.
Contextual Refinement between Concurrent Layers

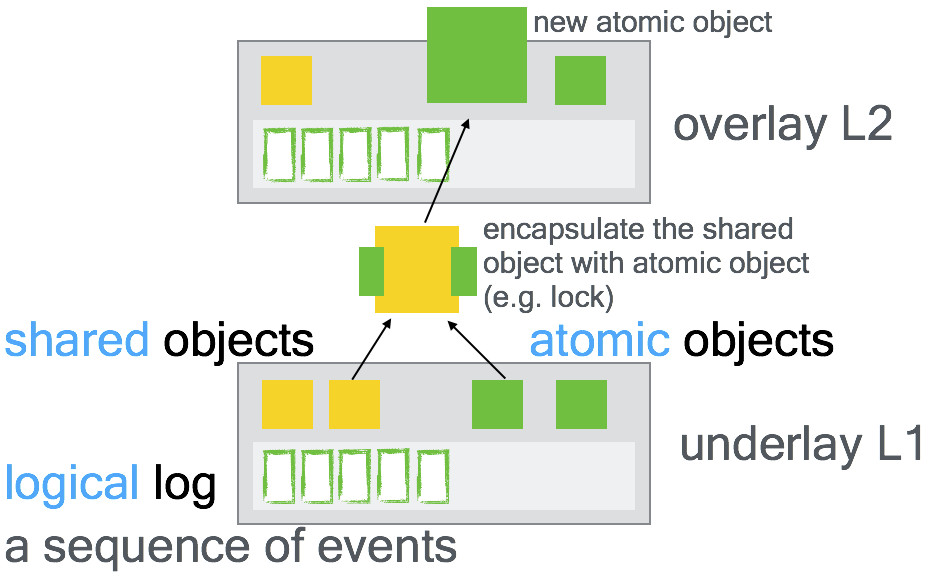
Extension of certified abstraction layer to reason about concurrent kernels.
- Private object: built from private module.
- Each CPU (or each thread) has its own private copy.
- It is similar to the certified abstraction layer in a sequential machine.
- Atomic object: well-synchronized shared memory, combined with operations over shared memory.
- Every atomic primitive in the overlay generates exactly one event, while its implementation may trigger multiple events.
- To construct an atomic object, we must reason about its implementation under all possible interleaving and prove that every acess to shared memory is well synchronized.
Machine Refinement

Machine refinement from multicore machine to CPU-local machine. It is a multicore machine lifting by abstracting away the low-level details of the concurrent CPUs with the following techniques:
- Logical log, hardware scheduler, and environment context.
- Push/pull model that logically represents read and write operations on shared memory.
This machine refinement makes us easy to build certified concurrent abstraction layers.
Step 1. Multicore machine model
This fine-grained multicore hardware model allows arbitrary interleavings at the level of assembly instructions.
- The hardware non-deterministically chooses one CPU at each step, and executes the next assembly instruction on that CPU.
- Three kinds of assembly instructions:
- atomic: the instruction involves an atomic object call.
- shared: the instruction involves on a non-atomic shared memory access.
- private: the instruction involves on only a private object/memory access.

Step 2. Machine model with hardware scheduler
A new machine model configured with a logical switch point and a hardware scheduler
- Logical switch point: appears in the position before each assembly instruction.
- Hardware scheduler
- Specifies a particular interleaving for an execution.
- Is a key concept to build a deterministic machine model.
- keeps consistency with the log by storing all the switch decisions made by this hardware scheduler in the log as switch events.
The machine model in this layer is general enough to capture all possible interleavings in the multicore machine because the machine model is parameterized over all possible hardware schedulers.

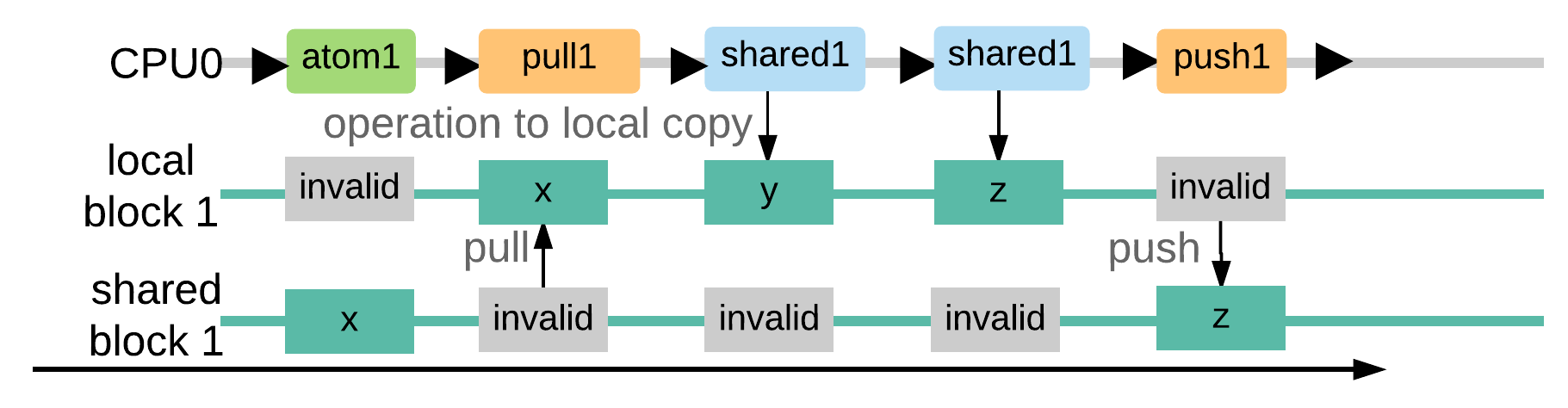
Step 3. Machine model with local copy of shared memory
The machine model that enforces well-synchronized accesses to shared memory
- Introducing a logical local copy of shared memory blocks along with a valid bit for each CPU.
- The relation between a CPU's local copy and the global shared memory is maintained through two logical primitives pull and push.
- pull: updates a CPU's local copy of that block to be equal to the one in the shared memory and invalidates the corresponding shared memory block.
- push: updates the shared version to be equal to the local block, marking the local block as invalid.
Step 4. Partial machine model with environmental context
The partial machine model that can be used to reason about the programs running on a subset of CPUs.
- It is parametrized with the behaviors of an environment context (i.e., the rest of the CPUs).
- It enables modular verification as well as proof linking of different local components to form a global claim about the whole system.
- It is configured with an active CPU set (A) and it queries the environmental context whenever it reaches a switch point that attempts to switch to a CPU outside the active set.
- Each environmental context is a response function, which takes the current log and returns a list of events from the context program (i.e., those outside of A).

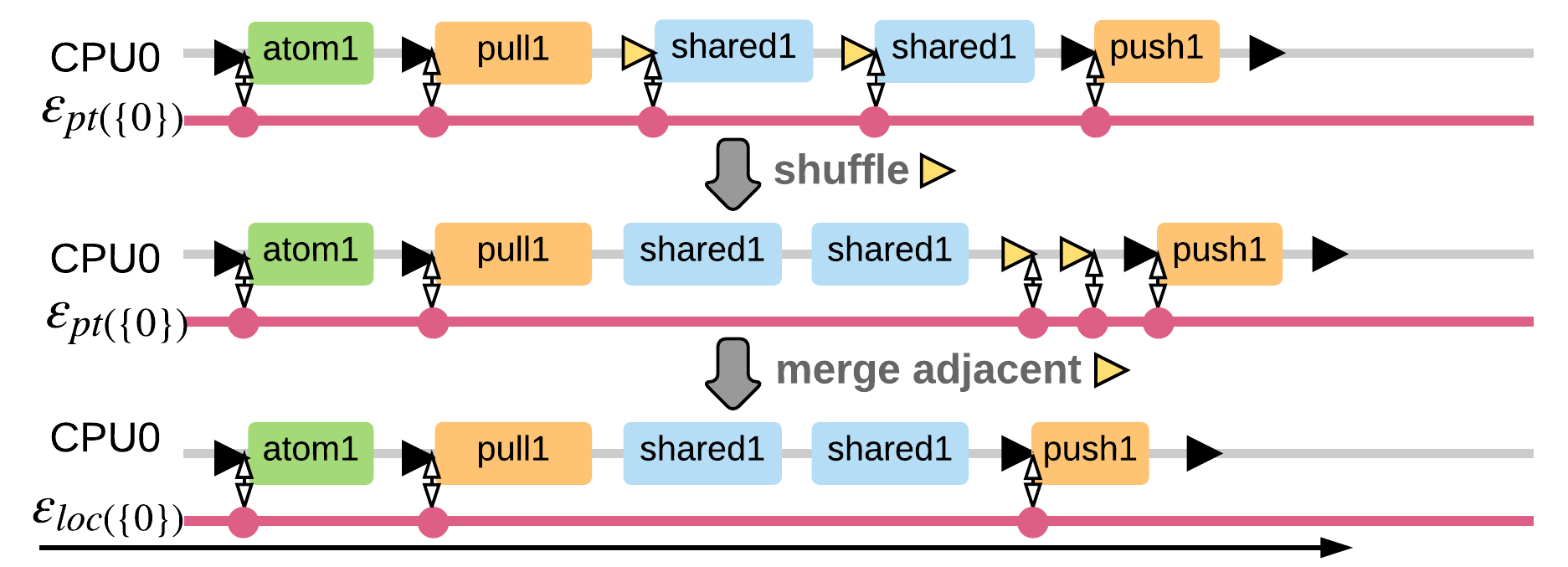
Step 5. CPU-local machine model
The last step is optimizations to easily use the abstraction layer approach on top of partial machine model with environmental context.
- Shuffling switch points When we perform shared or private operations, the observations of the environment context are delayed until the next atomic or push/pull operation.
- Merging switch points We merge all the adjacent switch points together as well as the switch events generated by the environment context.
Layer Calculus
Layer calculus can be used to build certified abstraction layer by composing smaller ones.

Vertical composition
- This composition is done at the level of the whole-machine contextual refinements obtained by applying the soundness theorem to each individual abstraction layers.
Horizontal composition
- With this rule, our abstraction layers are more compositional than regular modules.
- Layers L limits interactions among the different modules.
- For horizontal composition, the modules, M and N, need to have an identical state views.
Acknowledgements
This project is sponsored by NSF grants 1065451, 1521523, and 1319671, DARPA grants FA8750-16-2-0274 and FA8750-15-C-0082, DARPA CRASH grants FA8750-10-2-0254, and DARPA HACMS grants FA8750-12-2-0293. Any opinions, findings, and conclusions contained in this document are those of the authors and do not reflect the views of these agencies.