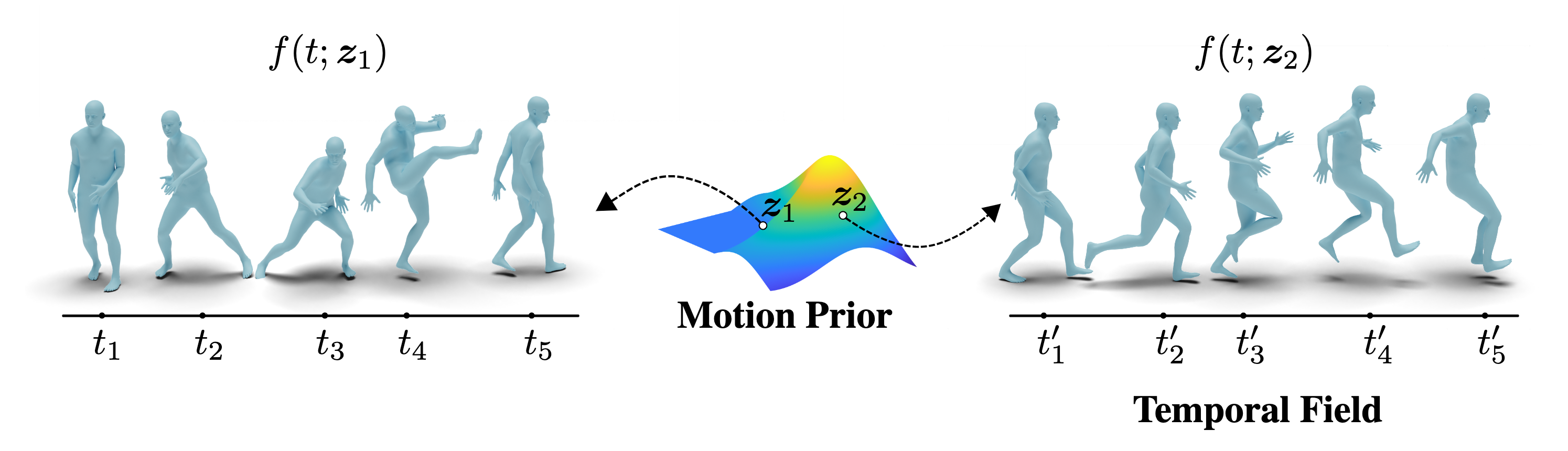
We present an implicit neural representation to learn the spatio-temporal space of kinematic motions. Unlike previous work that represents motion as discrete sequential samples, we propose to express the vast motion space as a continuous function over time, hence the name Neural Motion Fields (NeMF). Specifically, we use a neural network to learn this function for miscellaneous sets of motions, which is designed to be a generative model conditioned on a temporal coordinate \(t\) and a random vector \(z\) for controlling the style. The model is then trained as a Variational Autoencoder (VAE) with motion encoders to sample the latent space. We train our model with diverse human motion dataset and quadruped dataset to prove its versatility, and finally deploy it as a generic motion prior to solve task-agnostic problems and show its superiority in different motion generation and editing applications, such as motion interpolation, in-betweening, and re-navigating.
We first perform a sanity test to validate the reconstruction capability of our single-motion NeMF architecture. Here we present two examples of human motion and dog motion, respectively. Note that the dog motion contains 4336 frames (73 seconds) in total and we just render the first 900 frames for visualization.
Unlike other motion models, NeMF is a continuous motion model that can synthesize motion at different frame rates in theory. However, in practice, the dimension of the Fourier temporal features generated by positional encoding plays a critical role in the smoothness of motion. Here we show three comparisons of different dimensions to verify that a proper dimension choice can produce smooth motion even sampled at 240 fps.
Comparison with different architectures. In the seperate model, we let NeMF predicts the local motion and global orientation first and then predict the global translation, while alternatively, in the integrated model, the whole motion is predicted all together. Here we show that the integrated model tends to have sliding artifacts when being used in motion in-betweening tasks.
Comparison with other methods. Here we show the comparison of our method with HM-VAE and HuMoR for the motion reconstruction task. Note that HM-VAE fails to reconstruct a plausible result and HuMoR's result will gradually diverge. Our method achieves the best reconstruction result among these three methods.
Interpolation. Here we linearly interpolate the latent codes from the two motions on the side and visualize three samples in the middle. These results suggest the smoothness of our latent space which produces a smooth style changing while preserving the perceptual plausibility.
Composition. Since we disentangle the latent space for global root orientation and local motion, we can combine different global and local latent codes to create interesting new motions.
Motion Clips In-betweening Here we show the example of generating 30-frame inbetweens for 2 clips. We compare our results with SLERP, Inertialization, Robust Motion In-betweening (RMI) and HM-VAE.
AIST++ Dance In-betweening Here we show the example of generating transitions between two real dancing footages in AIST++.
Sparse Keyframe In-betweening Here we show the example of generating inbetweens for keyframes placed every 20 frames. We compare our results with SLERP and HM-VAE.
Here we show the example of redirecting the reference motion (yellow) to different synthetic trajectories (cyan).
@inproceedings{he2022nemf,
author = {He, Chengan and Saito, Jun and Zachary, James and Rushmeier, Holly and Zhou, Yi},
title = {NeMF: Neural Motion Fields for Kinematic Animation},
booktitle = {NeurIPS},
year = {2022}
}